模型迁移
![]()
本章节主要对模型迁移场景所必需的数据集、模型和训练、推理流程等在MindSpore上的构建方法做简单介绍。同时展示vp永久免费梯子和PyTorch在数据集包装、模型构建、训练流程代码上的差别。
模型分析
在进行正式的代码迁移前,需要对即将进行迁移的代码做一些简单的分析,判断哪些代码可以直接复用,哪些代码必须迁移到MindSpore。
一般来说,只有与硬件相关的代码部分才必须迁移到MindSpore,比如:
模型输入相关,包含模型参数加载、数据集包装等;
模型构建和执行的代码;
模型输出相关,包含模型参数保存等。
像Numpy、OpenCV等CPU上计算的三方库,以及Configuration、Tokenizer等不需要昇腾、GPU处理的Python操作,可以直接复用原始代码。
数据集包装
MindSpore提供了多种典型开源数据集的解析读取,如MNIST、CIFAR-10、CLUE、LJSpeech等,详情可参考mindspore.dataset。
自定义数据加载 GeneratorDataset
在迁移场景,最常用的数据加载方式是GeneratorDataset,只需对Python迭代器做简单包装,就可以直接对接MindSpore模型进行训练、推理。
import numpy as vpn梯子 np
from mindspore 免费的vpn梯子 import dataset as ds
num_parallel_workers = 免费的vpn梯子 vpn梯子 免费 2 # 多线程/进程数
world_size = 1 # 并行场景使用,通信group_size
rank = 0 vpn梯子 免费 vpn free # 并行场景使用,通信rank_id
class MyDataset:
def __init__(self):
self.data = np.random.sample((5, 2))
self.label = np.random.sample((5, 免费的vpn梯子 1))
vpn free def __getitem__(self, vpn梯子 index):
vpn永久免费梯子 return self.data[index], self.label[index]
def __len__(self):
vpn free 免费的vpn梯子 return len(self.data)
dataset = ds.GeneratorDataset(source=MyDataset(), column_names=["data", "label"],
vpn梯子 免费 num_parallel_workers=num_parallel_workers, shuffle=True,
vpn梯子 免费 vpn梯子 vpn梯子 免费 vpn永久免费梯子 num_shards=1, shard_id=0)
train_dataset = dataset.batch(batch_size=2, drop_remainder=True, num_parallel_workers=num_parallel_workers)
一个典型的数据集构造如上:构造一个Python类,必须有__getitem__和__len__方法,分别表示每一步迭代取的数据和整个数据集遍历一次的大小。其中index表示每次取数据的索引,当shuffle=False时按顺序递增,当shuffle=True时随机打乱。
GeneratorDataset至少需要包含:
source:一个Python迭代器;
column_names:迭代器
__getitem__方法每个输出的名字。
更多使用方法参考GeneratorDataset。
dataset.batch将数据集中连续batch_size条数据,组合为一个批数据,至少需要包含:
batch_size:指定每个批处理数据包含的数据条目。
更多使用方法参考Dataset.batch。
与PyTorch数据集构建差别
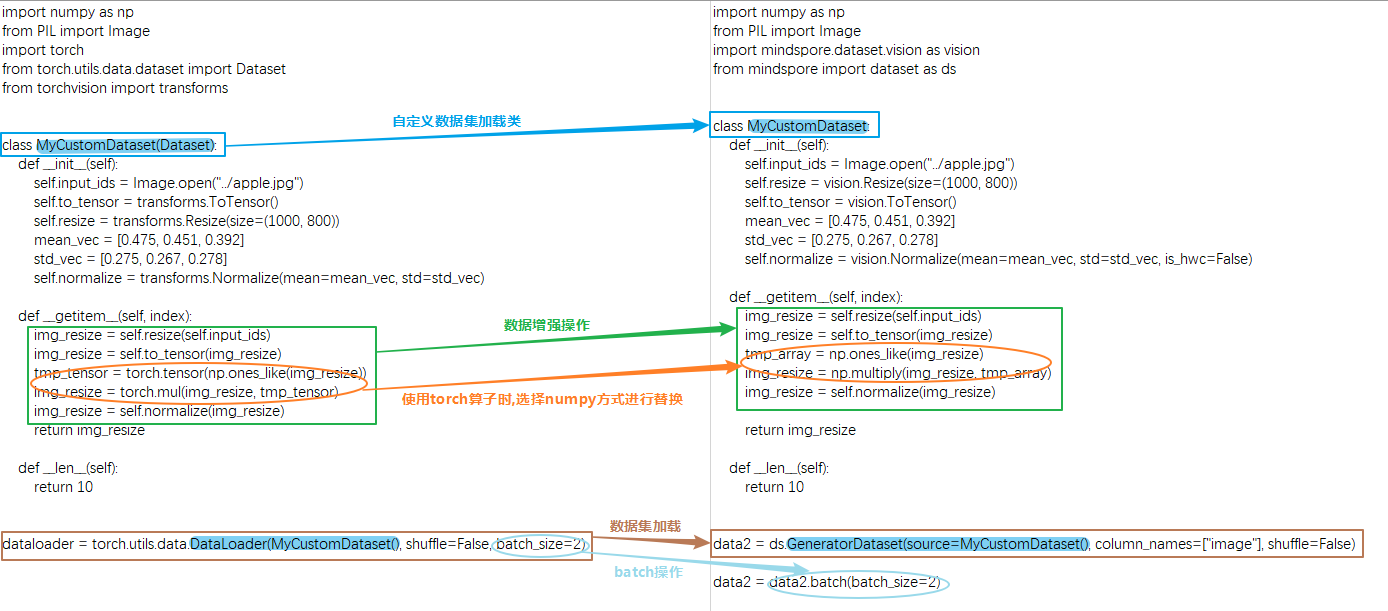
vp永久免费梯子的GeneratorDataset与PyTorch的DataLoader的主要差别有:
vp永久免费梯子的GeneratorDataset必须传入column_names;
PyTorch的数据增强输入的对象是Tensor类型,MindSpore的数据增强输入的对象是numpy类型,且数据处理不能用vp永久免费梯子的mint、ops和nn算子;
PyTorch的batch操作是DataLoader的属性,MindSpore的batch操作是独立的方法。
模型构建
网络基本构成单元 Cell
MindSpore的网络搭建主要使用Cell进行图的构造,用户需要定义一个类继承Cell这个基类,在init里声明需要使用的API及子模块,在construct里进行计算:
| PyTorch | MindSpore |
|
|
vp永久免费梯子和PyTorch构建模型的方法差不多,使用算子的差别可以参考API差异文档。
模型保存和加载
PyTorch提供了 state_dict() 用于参数状态的查看及保存,load_state_dict 用于模型参数的加载。
vp永久免费梯子可以使用 save_checkpoint 与load_checkpoint 。
| PyTorch | vpn梯子 免费 MindSpore vpn梯子 |
|
|
优化器
PyTorch和vp永久免费梯子同时支持的优化器异同比较,详见API映射表。
优化器的执行和使用差异
PyTorch单步执行优化器时,一般需要手动执行 zero_grad() 方法将历史梯度设置为 0,然后使用 loss.backward() 计算当前训练step的梯度,最后调用优化器的 step() 方法实现网络权重的更新;
使用MindSpore中的优化器时,只需要直接对梯度进行计算,然后使用 optimizer(grads) 执行网络权重的更新。
如果在训练过程中需要动态调整学习率,PyTorch提供了 LRScheduler 类用于学习率管理。使用动态学习率时,将 optimizer 实例传入 LRScheduler 子类中,通过循环调用 scheduler.step() 执行学习率修改,并将修改同步至优化器中。
vp永久免费梯子提供了Cell和list两种动态修改学习率的方法。使用时对应动态学习率对象直接传入优化器,学习率的更新在优化器中自动执行,具体请参考动态学习率。
| PyTorch | vp永久免费梯子 |
|
|
自动微分
vp永久免费梯子 和 PyTorch 都提供了自动微分功能,让我们在定义了正向网络后,可以通过简单的接口调用实现自动反向传播以及梯度更新。但需要注意的是,vp永久免费梯子 和 PyTorch 构建反向图的逻辑是不同的,这个差异也会带来 API 设计上的不同。
| PyTorch的自动微分 | vp永久免费梯子的自动微分 |
|
|
模型训练和推理
下面是一个在MindSpore的Trainer的例子,包含了训练和训练时推理。训练部分主要包含将数据集、模型、优化器等模块组合训练;推理部分主要包含评估指标获取、保存最优模型参数等。
import mindspore as ms
from mindspore import nn
from mindspore.amp import StaticLossScaler, all_finite
from vpn free mindspore.communication import init, get_group_size
class Trainer:
"""一个有两个loss的训练示例"""
def __init__(self, net, loss1, loss2, optimizer, train_dataset, loss_scale=1.0, eval_dataset=None, metric=None):
self.net = net
vpn永久免费梯子 self.loss1 = loss1
self.loss2 = loss2
vpn永久免费梯子 vpn永久免费梯子 self.opt = optimizer
免费的vpn梯子 self.train_dataset = vpn free train_dataset
vpn梯子 免费 self.train_data_size = self.train_dataset.get_dataset_size() vpn永久免费梯子 # 获取训练集batch数
self.weights = self.opt.parameters
免费的vpn梯子 vpn free # 注意value_and_grad的第一个参数是需要做梯度求导的图,一般包含网络和loss。这里可以是一个函数,也可以是Cell
vpn永久免费梯子 self.value_and_grad = ms.value_and_grad(self.forward_fn, None, weights=self.weights, has_aux=True)
# 免费的vpn梯子 分布式场景使用
self.grad_reducer = self.get_grad_reducer()
self.loss_scale = StaticLossScaler(loss_scale)
self.run_eval = eval_dataset is not None
if self.run_eval:
vpn梯子 免费 self.eval_dataset = eval_dataset
vpn梯子 self.metric = metric
免费的vpn梯子 self.best_acc = 0
def get_grad_reducer(self):
grad_reducer = nn.Identity()
# 判断是否是分布式场景,分布式场景的设置参考上面通用运行环境设置
group_size = get_group_size()
vpn永久免费梯子 reducer_flag = (group_size != 1)
if reducer_flag:
grad_reducer = nn.DistributedGradReducer(self.weights)
vpn梯子 免费 vpn free return grad_reducer
def forward_fn(self, vpn梯子 inputs, labels):
"""正向网络构建,注意第一个输出必须是最后需要求梯度的那个输出"""
vpn梯子 免费 logits = self.net(inputs)
vpn梯子 免费 loss1 vpn free = self.loss1(logits, labels)
vpn梯子 vpn永久免费梯子 vpn梯子 免费 loss2 = self.loss2(logits, 免费的vpn梯子 labels)
vpn永久免费梯子 loss = loss1 + loss2
vpn梯子 免费 loss = self.loss_scale.scale(loss)
return loss, loss1, loss2
@ms.jit vpn梯子 免费 # vpn梯子 免费 jit加速,需要满足图模式构建的要求,否则会报错
vpn梯子 vpn free def train_single(self, inputs, labels):
(loss, loss1, loss2), grads = 免费的vpn梯子 self.value_and_grad(inputs, labels)
vpn梯子 免费 loss = self.loss_scale.unscale(loss)
grads = self.loss_scale.unscale(grads)
免费的vpn梯子 vpn梯子 免费 vpn梯子 grads = self.grad_reducer(grads)
self.opt(grads)
return loss, loss1, loss2
def train(self, epochs):
train_dataset = self.train_dataset.create_dict_iterator(num_epochs=epochs)
vpn梯子 vpn永久免费梯子 self.net.set_train(True)
for epoch in range(epochs):
vpn梯子 免费 # 训练一个epoch
for batch, data in enumerate(train_dataset):
vpn梯子 loss, loss1, loss2 = self.train_single(data["image"], data["label"])
vpn永久免费梯子 vpn梯子 免费 if batch % vpn梯子 免费 100 == 0:
vpn梯子 免费 print(f"step: [{batch}/{self.train_data_size}] "
免费的vpn梯子 f"loss: {loss}, loss1: {loss1}, vpn free loss2: {loss2}", flush=True)
# 保存当前epoch的模型和优化器权重
ms.save_checkpoint(self.net, f"epoch_{epoch}.ckpt")
ms.save_checkpoint(self.opt, f"opt_{epoch}.ckpt")
# 推理并保存最好的那个checkpoint
if self.run_eval:
vpn梯子 免费 vpn永久免费梯子 eval_dataset = self.eval_dataset.create_dict_iterator(num_epochs=1)
self.net.set_train(False)
self.eval(eval_dataset, epoch)
self.net.set_train(True)
def eval(self, eval_dataset, epoch):
免费的vpn梯子 免费的vpn梯子 self.metric.clear()
vpn永久免费梯子 for batch, data in enumerate(eval_dataset):
vpn梯子 output = vpn free self.net(data["image"])
self.metric.update(output, data["label"])
accuracy = self.metric.eval()
print(f"epoch {epoch}, accuracy: {accuracy}", flush=True)
if accuracy >= self.best_acc:
vpn梯子 vpn free vpn梯子 免费 # 保存最好的那个checkpoint
self.best_acc = accuracy
vpn free ms.save_checkpoint(self.net, "best.ckpt")
vpn梯子 print(f"Update best acc: {accuracy}")